| Sugar4j mirrors the Java language using method calls, a "fluent interface" to create Java code with Java code.
Unlike other "Model-to-Text" engines (JSP, Velocity and the like), there is no need for external template files.
Dynamic code and static content are both contained in the same Java file.
Writing Sugar4j code should resemble most what programmers would write in plain Java.
There exists only a few special 'higher-level-constructs' to learn (like var, method or call). All other code just looks like Java. A Java programmer
is quickly able to 'read behind' the Sugar4j code and identify the relevant Java code parts of the template.
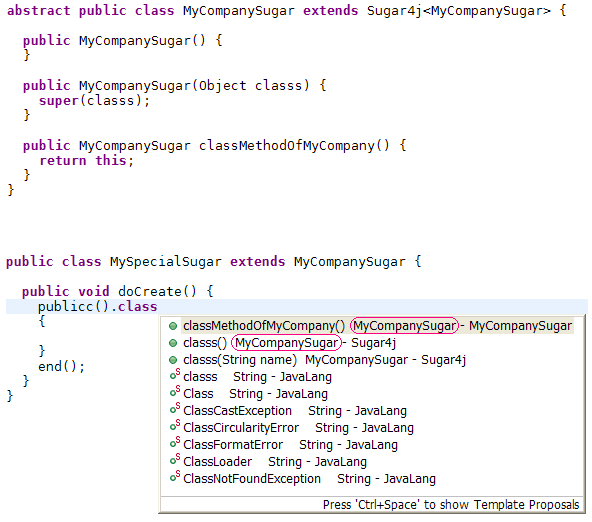
Sugar4j's naming scheme is quite special.
Using a fluent interface, the obvious name for a method to output the public keyword would be public().
But that's not possible. So what name then closest looks like public? The answer is: publicc
But why?
|
Arcicondg to a reheeasrcr at an Eligsnh uvitneirsy, it deson't meattr
in what oderr the ltetres in a word are, the only irmapontt tinhg is
that frsit and last leettr is at the rghit pacle.
The rest can be a ttaol mess and you can siltl read it whotuit pbloerm.
This is baucsee we do not read eervy leettr by it self but the word as a wolhe.
|
More on this topic can be found here.
You can even try it out yourself here.
So according to this amazing study, the ideal name is publicc. Except for the last character, everything is the same. If you want public in the output,
just start writing public.
For every Java keyword, there exists a method with the same name but it's last character appended. new becomes neww(),
class becomes classs(), throws becomes throwss().
The same naming scheme is applied to primitive types and literals: intt,
booleann, doublee, truee, falsee, nulll.
For a complete list see Javadoc sugar4j.lang.JavaLang.
Another unique pattern of Sugar4j is to make extensive use of the Java 5.0 varargs feature.
Where appropriate, the varargs array elements are treated as Pairs. In a method declaration, for instance,
the method parameters are expected to occur in type-name pairs:
The name "Sugar4j" originated from asking the question: What other stuff does one need for a cup of Java? You have the jar, you have the beans...and I personally don't like my coffee without sugar.
A second meaning comes from the terms "adding syntactical sugar" or "...is only syntactical sugar".
To be precise: Sugar4j is rather syntactical salt, but I just don't like salt in my coffee :)
These are the main advantages of Sugar4j:
- Having only one source file means maintaining only one source file, only one programming language to learn/understand, only one editor: the one you use the most because it is the best.
-
Parameter documentation. At some point you must access your dynamic data within your template. Without such a feature, the whole thing does not make sense.
This data is made available mostly using prefixed identifiers such as #className or $member.
Where are those parameters documented? Are they even used anymore? In Sugar4j you use Java and Javadoc.
- Reference analysis and refactoring. External text templates behave contrarily to a source file's life cycle.
80% of a source file's life cycle is spent in maintaining it.
Only 20% for it's initial creation. A template is created very fast. Take some sample class,
replace all occurences of "XXX" to "<%= className %>", put a loop around it, save it as "MyClass.jsp" and your done.
But later you must add new features to it, the String list is'nt sufficent anymore. You must introduce a new class.
Which code is affected? Who needs that variable again? I better copy and paste that code.
So in 80% of the time it is hard to program. Only if 20% of the time it is cool.
Creating a Sugar4j class is (relative) hard in 20% of the time, and cool in 80% of the time!
It's seems hard to write 'begin()' instead of '{'. Yes, but you get used to it. With some routine your eye simply identify
'begin()' as being '{'. There's no need to read it. The more imporant thing is the indent
level, which precisely shows the structure of your program. Thanks to your one and only code formatter.
String handling
Under the hood, Sugar4j "just" appends strings to an internal buffer. Some effort has been made
to reduce the use of string literals and provide convenient ways to pass identifiers rather than strings.
Most Sugar4j methods expects parameters of type Object. If such an Object
is a java.lang.Class or java.lang.Package instance, its full qualified name is used. In every other case, Object's toString() is used.
This allows you to pass a Class's class member to, for example, a variable declaration.
Instead of writing:
var("java.io.Reader", "reader");
|
You can write:
var(Reader.class, "reader");
|
With Package Content Interfaces you can even write:
The cool thing here is, that the Sugar4j class not only contains its own import
list, but the import list of the resulting code as well. Unless you use the Import Manager or add imports by yourself, the resulting code does not have an import list; all names are full qualified.
Package Content Interfaces
To further reduce to use of string literals, Sugar4j provides generated interfaces (generated with Sugar4j of course),
which contain string constants for all public classes and fields of the JRE (1.6.0_03 at the time of writing).
Code taken from sugar4j.lang.JavaLang:
package sugar4j.lang;
public interface JavaLang {
...
public static final String String = "String";
public static final String Integer = "Integer";
...
}
|
Sugar4j directly implements the sugar4j.lang.JavaLang and sugar4j.lang.JavaUtil interfaces.
While you are within a Sugar4j method like doCreate(), the well known "Integer" suddenly seems to behave strangely...
| What do you think? Would this code compile? |



|
Reveal Solution
And the solution is...
to use full qualified names.
Depending on the context used, the string constant shadows the java.lang.Integer class name.
You can use Package Content Interfaces in your Sugar4j subclass by
- implementing the interface. All identifiers of that interface are now in the namespace of your Sugar4j subclass. This is the equivalent of a Java import on demand.
- making a static import to specific identifiers. This is the equivalent of a regular Java class import.
Implement JavaIo. This is like import java.io.*:
import sugar4j.Sugar4j;
import sugar4j.lang.JavaIo;
public class MyIoSugar extends Sugar4j<MyIoSugar> implements JavaIo {
public MyIoSugar() {
super("tutorial.MyIo");
}
public void doCreate() {
publicc().classs().begin();
{
publicc().method(Reader, "createReader").begin();
{
var(Reader, "reader").assign().neww(FileReader, "/myfile.txt").eos();
returnn("reader").eos();
}
end();
}
end();
}
}
|
Using a static import. This is like a qualified import:
import sugar4j.Sugar4j;
import static sugar4j.lang.JavaIo.Reader;
import static sugar4j.lang.JavaIo.FileReader;
public class MyIoSugar extends Sugar4j<MyIoSugar> {
public MyIoSugar() {
super("tutorial.MyIo");
}
public void doCreate() {
publicc().classs().begin();
{
publicc().method(Reader, "createReader").begin();
{
var(Reader, "reader").assign().neww(FileReader, "/myfile.txt").eos();
returnn("reader").eos();
}
end();
}
end();
}
}
|
The return of begin / end
You may remember the days of Pascal and Modula-2 where blocks begin with BEGIN and end with END?
Now we have the best of both worlds :)
begin() outputs the left curly brace, end() outputs the right curly brace.
We strongly encourage you to use nested blocks within
the begin() and end() calls to improve readability of the structure of the sugar class.
protectedd().method(voidd, "doIt").begin();
{
}
end();
|
Sugar4j type argument
The Sugar4j class requires a type argument T, which must be the same as the concrete Sugar4j subclass.
Most of the Sugar4j methods return the this instance T, so that the fluent interface style can be achieved.
The advantage of the template parameter T is that developers can introduce an own subclass of Sugar4j, and all those
methods returning T return now the concrete subclass. This is convenient if you add more methods to your subclass, as
they are immediately available without casting or overriding every method using 'arity' methods.
We suggest you to introduce a subclass in your company/project and further derive from that subclass instead directly from Sugar4j.
Decorator methods
Most of the Sugar4j methods add strings directly to the output buffer.
Decorator methods on the other hand do not add to the output buffer, but return a string which is then later added.
Such a decorator method enriches type or variable names with more information.
A decorator method is always static. All array* methods are decorators, the expr, typeArg, get, quote just to name a few.
The arrayOf decorator adds brackets ([]) to the given String:
var(arrayOf(String), "strings").eos();
|
Generating sugar code
The first real-life usage of Sugar4j was to build a generator that takes an existing Java class, parses it and creates sugar code which in turn creates that existing class again.
With a regular template engine, you'll first create a working Java class, rename it to something like "MyClass.jsp" and put all the dynamic code in it.
Using the sugar generator, you'll also first create a working Java class, feed it to the sugar generator and put all the dynamic code into the generated sugar code.
The sugar generator uses Eclipse JDT for parsing/analyzing the Java AST. Sugar4j itself does not depend on JDT, only the generator does.
Although you can use the generator without Eclipse, enhanced IDE support for generating sugar code is available within Eclipse.
Demos on how to use Sugar4j and the Sugar4j Generator are available in the Downloads section.
|